



实时云渲染预启动技术解析:UE数字孪生应用的延迟优化机制(一)
2026-05-26 17:31
在实时云渲染架构中,基于UE构建的大型数字孪生应用普遍面临“首次启动延迟”这一工程痛点。UE引擎冷启动需经历资源加载、Shader编译、场景初始化等阶段,单次耗时可达分钟级,严重制约数字孪生场景对实时交互的要求。Paraverse平行云自研的实时云渲染平台LarkXR自带预启动功能,通过实例预热与智能调度机制,将启动延迟从用户请求的关键路径中剥离。本文从技术角度对该功能的设计原理、调度策略及工程价值展开分析。
一、实时云渲染下数字孪生应用的启动延迟问题
1. UE数字孪生项目在云渲染架构中的冷启动瓶颈
在实时云渲染架构中,UE应用实例运行于云端GPU节点,终端通过WebRTC协议接收编码后的音视频流,并回传键鼠或触控指令。当一个未初始化的UE项目收到用户访问请求时,系统须依次完成:分配GPU资源、启动UE引擎进程、加载项目文件、实时渲染推流画面到客户端等步骤。对于包含高精度模型与复杂材质的数字孪生项目,该流程的耗时构成用户体验的显著断层,尤其在工业仿真与城市级CIM平台中,单次冷启动的十几分钟的延迟难以满足交互式访问的需求。
1. 资源加载耗时:大型数字孪生项目包含高精度模型、8K纹理、复杂材质,GPU显存上传与资源反序列化过程在冷启动时需要完整执行,无法跳过或并行化处理。
2. Shader编译延迟:UE引擎首次运行需编译大量Shader变体,在无缓存情况下可占用数分钟启动时间。
3. 云端感知放大效应:相比本地启动,云渲染架构下用户通过网络等待远程实例就绪,延迟不仅包含引擎启动耗时,还叠加了信令协商与流建立时间,感知更为明显。
2. 启动延迟对数字孪生产品化交付的制约
打断实时决策链路:在应急会商、远程调度等场景中,分钟级的加载等待构成非技术性中断,削弱数字孪生“实时映射、即时决策”的核心价值。
限制并发访问规模:冷启动机制下,应用实例无法提前就绪,系统难以在流量高峰时段快速扩容,并发能力受制于单次启动耗时。
增加演示与推广阻力:对外演示时“请稍等加载”的体验,直接降低客户对数字孪生产品成熟度的信任感,抬高商务沟通门槛。
将数字孪生应用从本地部署迁移至云端,解决了“能否跑起来”的可用性问题,但启动延迟的存在,在演示汇报、远程协作、应急会商等场景中,等待应用加载的时间窗口可能造成决策链路的非技术性中断。如何将应用启动耗时从用户感知的关键路径中剥离,成为实时云渲染平台在数字孪生领域深入应用的前提条件。
二、实时云渲染平台LarkXR预启动功能的技术机制
1. 预启动的系统架构
离线预热机制:节点代理在GPU节点上提前启动UE应用进程,完成引擎初始化、场景加载与渲染管线就绪,将实例状态标记为“可用”后注册至资源池。
GPU资源池化支撑:底层通过GPU池化与进程级隔离技术,使多个预启动实例安全共享同一物理GPU,显存与算力隔离互不抢占。
请求路径简化:用户请求到达时,调度层直接分配已就绪实例并建立WebRTC连接,将冷启动流程从同步链路中完全移除,实现秒级响应。

2. GPU资源池智能调度策略
参数化池配置:支持设定最小空闲实例数与最大实例总数,系统根据实时并发量动态调整池内实例数量,平衡响应速度与资源成本。
动态伸缩控制:空闲实例低于最小阈值时自动触发补充预热,高于上限时逐步回收,配合等待时间参数抑制边界条件下的频繁启停抖动。
心跳健康检测:每个预启动实例定期上报心跳,系统可检测应用卡死或进程异常退出,自动触发实例重建,确保池内实例真实可用。

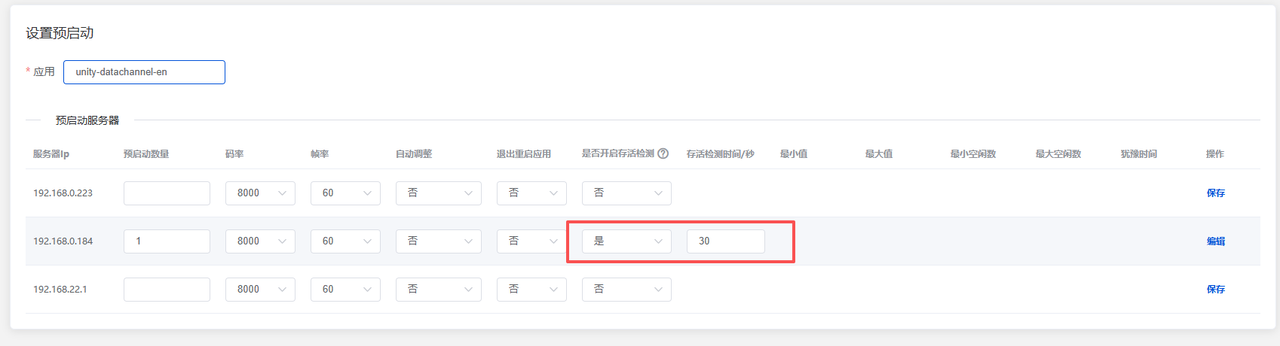
预启动的有效实施依赖于对资源池的动态调控。LarkXR允许为每个应用定义最小空闲实例数与最大实例数两个关键参数,调度器持续监控池中实例的占用情况












